

Obsah
|
...příkladem je vyhledávací mechanismus, který najdete v levém sloupci...
Vyhledávací stroj je králem navigačních mechanismů. Uživatel zadá slovo, které jej zajímá, a dostane menu stránek, na nichž se dotyčné slovo vyskytuje. Pravděpodobnost, že mezi nabídnutými stránkami najde svou vyvolenou, je velmi vysoká.
Studie chování uživatelů ukázaly, že někteří z nich jednoznačně dávají přednost
použití vyhledávacích mechanismů před čímkoli jiným. Takový uživatel se ihned
po vstupu na server shání po vyhledávači a jeho prostřednictvím pak hledá
stránky, které jej zajímají. Obvyklá struktura odkazů jej nechává zcela
chladným. Podle zmíněné studie se tímto způsobem chová až pětina uživatelů.
Faktem je, že hledáte-li něco konkrétního na velkém serveru, je použití
vyhledávacího mechanismu široko daleko nejrychlejší.
Realizovat lokální vyhledávač je samozřejmě daleko jednodušší. Pravděpodobně vystačí s pár megabajty diskového prostoru a procesor také příliš nezatíží, protože těžko bude dostávat desítky dotazů za sekundu a jejich vyřízení také nepotrvá nijak dlouho. Velkou výhodou lokálních vyhledávačů je, že prohledávaných stránek není mnoho a jsou blízko. Díky tomu je možné aktualizovat data v prohledávači velmi často, zpravidla denně.
Nejvýznamnějším problémem, komplikujícím instalaci vyhledávacích strojů, je
nutnost speciálního programového vybavení. Chcete-li prohledávat svůj server,
budete potřebovat program, který tuto činnost zajistí. Zatím nelze říci, že by
člověk o takové programy zakopával na každém rohu. Jednou z prvních vlaštovek
je Web Parker Jiřího A. Randuse. Jak název napovídá, jedná se o příbuzného
programu Nosey Parker, který již pár let prohledává domácí FTP archivy (viz
Základní uspořádání typického vyhledávacího mechanismu znázorňuje obrázek 1. Skládá se ze tří hlavních částí: programu pro sběr dat, databázového stroje a programu pro vyřizování uživatelských dotazů. Jádrem celého vyhledávače jsou data o obsahu prohledávaných stránek. Ta jsou obsluhována jakýmsi databázovým strojem, zajišťujícím jejich vytvoření, aktualizaci a odpovídajícím na dotazy. Může se jednat o skutečný databázový systém nebo pouze o části kódu, vestavěné do ostatních obslužných programů.
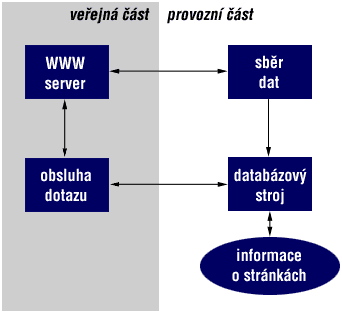 Obrázek 1: Struktura vyhledávacího mechanismu K vytvoření databáze slouží program pro sběr dat. Zpravidla se mu předloží jako výchozí jistá stránka. Sběrač ji načte ze serveru a její obsah předá k uložení do databáze. Většinou se ukládají jednotlivá slova ze stránky, případně doplněná o priority (slovo v nadpisu má větší váhu než v obyčejném textu). Kromě toho však sběrač vyhledá na stránce všechny odkazy a s nimi postupně provede totéž. Zpravidla přitom dodržuje jisté hranice. Například bere v úvahu jen odkazy, neopouštějící daný server nebo jeho část. Sběrač tedy postupně odešle do databáze kompletní obsah celé skupiny dokumentů, dosažitelných z výchozí stránky. Pro jejich získání přitom komunikuje s WWW serverem zcela obvyklým způsobem - protokolem HTTP. Tváří se vůči němu jako obyčejný WWW klient.
Když je databáze vytvořena, může nastat fáze dotazování. Její viditelnou částí
je formulář, umožňující uživateli zadat hledaný text. Zpracovávající program
pak na základě zadaného řetězce nechá vyhledat všechny výskyty dotyčného slova
a uživateli odešle jejich seznam. Tento obslužný program se vyvolává obvyklým
způsobem - mechanismem CGI.
pod názvem webparker.tgz. Instalace odpovídá zvyklostem Unixu -
distribuci musíte rozbalit, upravit konfiguraci a přeložit. O rozbalení se
postará příkaz
V aktuálním adresáři vznikne podadresářtar xzvf webparker.tgz webparker a do něj budou
uloženy všechny části programu. Nyní je třeba přizpůsobit konfiguraci vašim
podmínkám. To zahrnuje dva zásahy do konfiguračních souborů. První se týká
souboru Makefile, v němž musíte upravit obsah proměnné
PATHTOINDEXES. Obsahuje jméno adresáře, ve kterém mají sídlit
databázové soubory. Webparker má jeho název pevně uložen ve svých programech.
Pokud tedy chcete na svém serveru nezávisle prohledávat několik částí, musíte
program přeložit několikrát, pro každé hledání s jiným adresářem.
Doporučuji vytvořit si vyhrazený adresář, v němž bude umístěno vše, co s
vyhledávací službou souvisí - řekněme
Druhý konfigurační zásah se týká souboru Jakmile máte upraveny konfigurační soubory, nechte program přeložit příkazem V aktuálním adresáři vznikne skupina proveditelných programů, tvořících jádro Webparkeru. Nyní nastává fáze rozsévání. Je třeba umístit soubory na správná místa.make
Skrytou část, která realizuje sběr dat a vytvoření databáze, doporučuji umístit
do společného adresáře s databází, tedy
Jakmile máte programy umístěny, vytvořte databázi. Spusťte program
Do databáze budou zařazeny všechny stránky, na které se lze dostat (byť zprostředkovaně) ze zadané stránky a začínají uvedeným URL. Lokátorů může být několik. Pokud například chcete prohledávat dokumentaci, která sídlí v adresáříchwebparker http://www.kdesi.cz/ /doc a /help, zadejte
Když program skončí svou práci, vytvoří v zadaném adresářiwebparker http://www.kdesi.cz/doc/ http://www.kdesi.cz/help/ /net/www/search tři soubory, tvořící databázi. Aby se její stav
udržoval v aktuální podobě, doporučuji spouštět webparker denně v nočních
hodinách. K tomu poslouží věrný crontab.
Závěrečnou fází instalace je zpřístupnění vyhledávače uživatelům. O spolupráci
s nimi se starají pouhé dva soubory z distribuce: stránka s formulářem pro
zadání hledaného řetězce znaků a zpracovávající CGI program. Ukázkový formulář
najdete v souboru
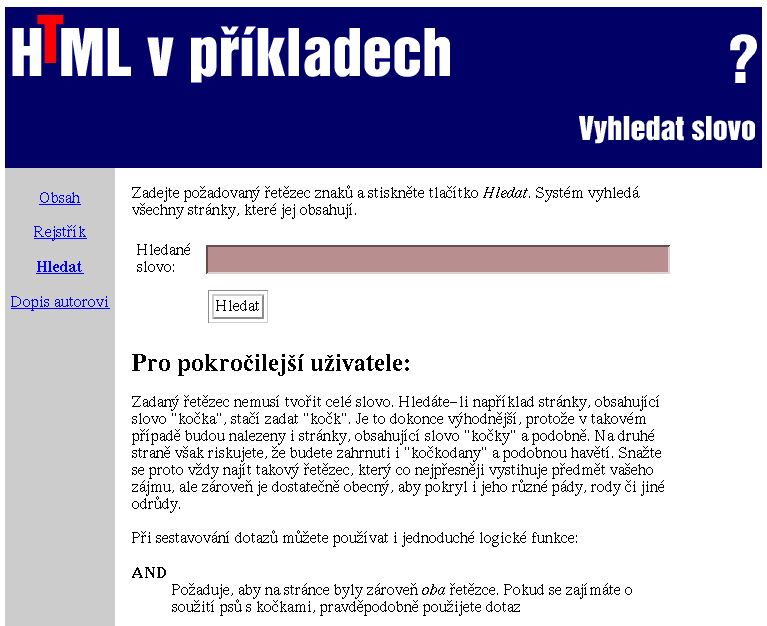 Obrázek 2: Formulář pro dotaz Webparkeru
Zpracovávající program, nazvaný
Vzhled výsledků, které program search generuje, nelze ovlivnit. Můžete je však
"obalit" stránkou a přizpůsobit tak celkovou podobu výsledkových stránek vašim
konvencím. K tomu slouží soubory
Tím je Webparker instalován. Stačí jej vyzkoušet a dát k dispozici uživatelům.
Je záhodno, aby odkaz na vyhledávání byl zařazen pokud možno na každou stránku
vašeho serveru či prezentace. Pokud používáte navigační lištu, zcela jistě do
ní vyhledávání přidejte.
Při zadávání hledaného výrazu můžete používat základní logické funkce. Slouží k
tomu obvyklá anglická slova kočka AND pes OR požaduje, aby na stránce byl alespoň jeden z řetězců. Pokud
chováte psy a kočky a chcete se dozvědět něco zajímavého o těchto domácích
zvířatech, pravděpodobně vám poslouží
kočka OR pes NOT pak označuje negaci - vyhoví stránky, které neobsahují
řetězec. Zpravidla se používá v kombinaci s dalšími logickými výrazy, protože
samotná negace by představovala příliš slabou podmínku. Řekněme, že máte v
lásce psy, ale kočky nemůžete ani cítit. V tom případě je pro vás určeno
Webparker bohužel v současné době nedává přednost žádné z logických funkcí a vyhodnocuje je zleva doprava. Nejsou k dispozici ani závorky, které by umožňovaly toto chování změnit. Pokud se zajímáte o soužití psů s kočkami nebo se včelami, nemůžete svůj dotaz formulovatpes NOT kočka Nejprve by se totiž provedlopes AND kočka OR včela AND a teprve na jeho výsledek by bylo
uplatněno OR. Takže byste obdrželi stránky obsahující současně
"pes" a "kočka" nebo řetězec "včela" (zde však mizí požadavek na výskyt psa).
Kýženého chování dosáhnete změnou pořadí:
Zde se nejdříve vyhodnotí, zda stránka obsahuje kočku či včelu a pak se ještě přidá podmínka, že zároveň na ní musí být pes.kočka OR včela AND pes
Zajímavým problémem pro domácí podmínky je, jak se vyhledávací stroj vyrovná s
kódováním češtiny. Webparker řeší tuto úlohu odháčkováním. U zkoumaných
dokumentů automaticky určuje jejich kódování a následně je převádí do
standardního ASCII kódu, tedy odstraňuje diakritická znaménka. Vyhledávaný
řetězec je proto třeba vždy zadávat bez háčků a čárek.
|